Your voice AI agent sounds like a robot reading a script.
Every awkward pause. Every unnatural response. Every time it talks over customers or misses emotional cues. These aren't just technical glitches; they're trust destroyers that send customers straight to your competitors.
Here's what most businesses don't realize: The difference between a voice AI agent that frustrates customers and one that delights them isn't the underlying model; it's how you engineer the prompts that guide voice-specific conversations.
The breakthrough: Proper voice AI prompt engineering can reduce response latency from 1,500ms to under 200ms, eliminate 93% of conversation breakdowns, and transform robotic automation into natural human-like interactions that customers prefer over traditional phone trees.
The Hidden Cost of Poor Voice AI Prompt Engineering
What Bad Voice Prompts Are Actually Costing You
Direct Business Impact:
5.91% average call abandonment rate with traditional phone systems experiencing 3+ minute hold times (Global Contact Center data, 2025)
35% of business calls happen after hours, most going to voicemail and lost to competitors (Industry research, 2025)
16% reduction in customer satisfaction for each second of latency in voice interactions (Voice AI performance research, 2025)
75% of customers expect voice AI to handle calls by 2025, with human-like naturalness as the baseline expectation (Banking AI case studies, 2025)
Hidden Operational Costs:
Conversation repair overhead: Poor turn-taking and interruption handling require 3-5x more dialogue turns to complete simple tasks
Escalation waste: Voice agents without proper guardrails escalate 40-60% of calls unnecessarily, overwhelming human staff
Customer trust erosion: Robotic or unnatural voice interactions damage brand perception and reduce repeat engagement
Competitive disadvantage: Businesses with optimized voice agents capture after-hours opportunities while competitors sleep
Why Generic Voice AI Implementations Fail
Problem 1: Text Prompts Applied to Voice
Prompts designed for text chatbots create verbose, unnatural spoken responses
Voice AI requires conciseness; customers can't skim or re-read audio
Lack of prosody guidance creates monotone, robotic delivery
No consideration for verbal clarity (spelling out emails, confirming numbers)
Problem 2: Ignoring Real-Time Conversation Dynamics
No turn-taking strategy leads to awkward interruptions and talking over customers
Missing Voice Activity Detection (VAD) creates unnatural pauses or premature cutoffs
Failure to handle barge-ins when customers interrupt mid-response
No emotion detection to adapt tone based on customer frustration or satisfaction
Problem 3: Latency Blindness
Response times over 500ms feel unnatural and robotic to customers
Poor token management wastes processing time on unnecessary verbosity
Inefficient retrieval systems add 1-2 seconds to every response
No optimization for streaming responses that begin speaking while still processing
The Science of Effective Voice AI Prompt Engineering
Core Principles That Drive Natural Conversations
Speed Over Perfection: Research from ElevenLabs and Deepgram demonstrates that voice AI response latency under 200ms is critical for natural conversation flow. Customers perceive delays of 300ms or more as "thinking time" that breaks immersion and reduces trust (Voice AI latency benchmarks, 2025).
Conversational Brevity: Voice-optimized prompts produce responses 60-70% shorter than text equivalents while maintaining clarity. The average human attention span for spoken information is 8-10 seconds before comprehension drops significantly (ElevenLabs Prompting Guide, 2025).
Emotion-Aware Adaptation: Real-time sentiment analysis enables voice agents to detect frustration, confusion, or satisfaction and adjust tone accordingly. Systems with emotion detection improve customer satisfaction scores by 35% compared to static-tone agents (Sentiment Analysis research, 2025).
Proven Techniques That Create Human-Like Voice Agents
1. Voice-Specific System Prompts
What It Is: Structuring system prompts specifically for spoken conversation, with explicit guidance on pacing, tone, interruption handling, and verbal clarity.
Why It Works:
Eliminates verbose "chatbot speak" that sounds unnatural when spoken aloud
Provides clear boundaries for when to speak, pause, and listen
Defines personality traits that translate to voice (warm, professional, empathetic)
Establishes fallback behaviors for conversation breakdowns
Real-World Application:
You are a professional customer service agent speaking naturally over the phone.
VOICE GUIDELINES:
Keep responses under 3 sentences unless explaining complex stepsUse natural filler words occasionally ("actually," "essentially," "let me check")Pause briefly after asking questions to allow customer responseSpell out emails as "username at domain dot com"Confirm numbers by repeating them clearly: "That's 5-5-5, 1-2-3, 4-5-6-7"
CONVERSATION FLOW:
Listen for natural pauses before responding (don't interrupt)If customer interrupts you, stop immediately and listenAcknowledge emotions: "I understand this is frustrating" when detecting negative sentimentAsk one question at a time, never stack multiple questions
TONE ADAPTATION:
Frustrated customer → Empathetic, solution-focused, calmConfused customer → Patient, clear, step-by-step guidanceSatisfied customer → Warm, efficient, positive reinforcement
Results: Voice-specific system prompts reduce conversation repair attempts by 67% and improve first-call resolution by 42% (Vapi Voice AI optimization research, 2025).
2. Turn-Taking and Interruption Management
What It Is: Implementing Voice Activity Detection (VAD) and turn-taking endpoints that enable natural conversation rhythm, including handling customer interruptions gracefully.
Why It Works:
Prevents awkward talking-over situations that frustrate customers
Allows customers to interject naturally, like they would with humans
Reduces perceived latency by responding immediately when the customer finishes speaking
Creates conversational flow that feels intuitive rather than scripted
Implementation:
TURN-TAKING RULES:
Use phrase endpointing to detect natural sentence completionWait 300-500ms after customer stops speaking before respondingIf customer speaks again during wait period, reset and listenEnable barge-in: If customer interrupts mid-response, stop immediately
INTERRUPTION HANDLING:
When interrupted:
Stop speaking within 200msAcknowledge: "Go ahead" or "I'm listening"Process new input and adapt response accordinglyDon't resume previous response unless customer asks
SILENCE MANAGEMENT:
After 3 seconds of silence: "Are you still there?"After 6 seconds: "I'm here when you're ready"After 10 seconds: "I'll call you back if we get disconnected"
Results: Proper turn-taking reduces conversation duration by 28% while improving customer satisfaction by 35% (Turn-taking research, LiveKit, 2025).
3. Latency Optimization Through Prompt Engineering
What It Is: Structuring prompts to minimize token usage, enable streaming responses, and reduce processing time while maintaining conversation quality.
Why It Works:
Every token processed adds latency; concise prompts respond faster
Streaming allows the agent to begin speaking while still generating a complete response
Reduced context window usage enables faster model inference
Optimized retrieval queries return relevant information in milliseconds
Token Optimization Strategies:
INEFFICIENT (127 tokens, 1,200ms latency):
"I want to take a moment to express my sincere gratitude for your patience while I look into this matter for you. I understand that your time is valuable, and I truly appreciate you giving me the opportunity to assist you with your inquiry today. Let me go ahead and check our system to see what information I can find regarding your question about your account status."
OPTIMIZED (18 tokens, 200ms latency):
"Let me check your account status. One moment."
[Retrieves information]
"Your account is active with a balance of $47.23. Anything else I can help with?"
Context Window Management:
PROMPT STRUCTURE FOR SPEED:
Core instructions: 200-500 tokens maximumDynamic context: Only inject relevant retrieved informationConversation history: Last 3-5 turns only (not entire conversation)Remove redundant information after each turnUse prompt caching for static instructions (reduces latency by 40%)
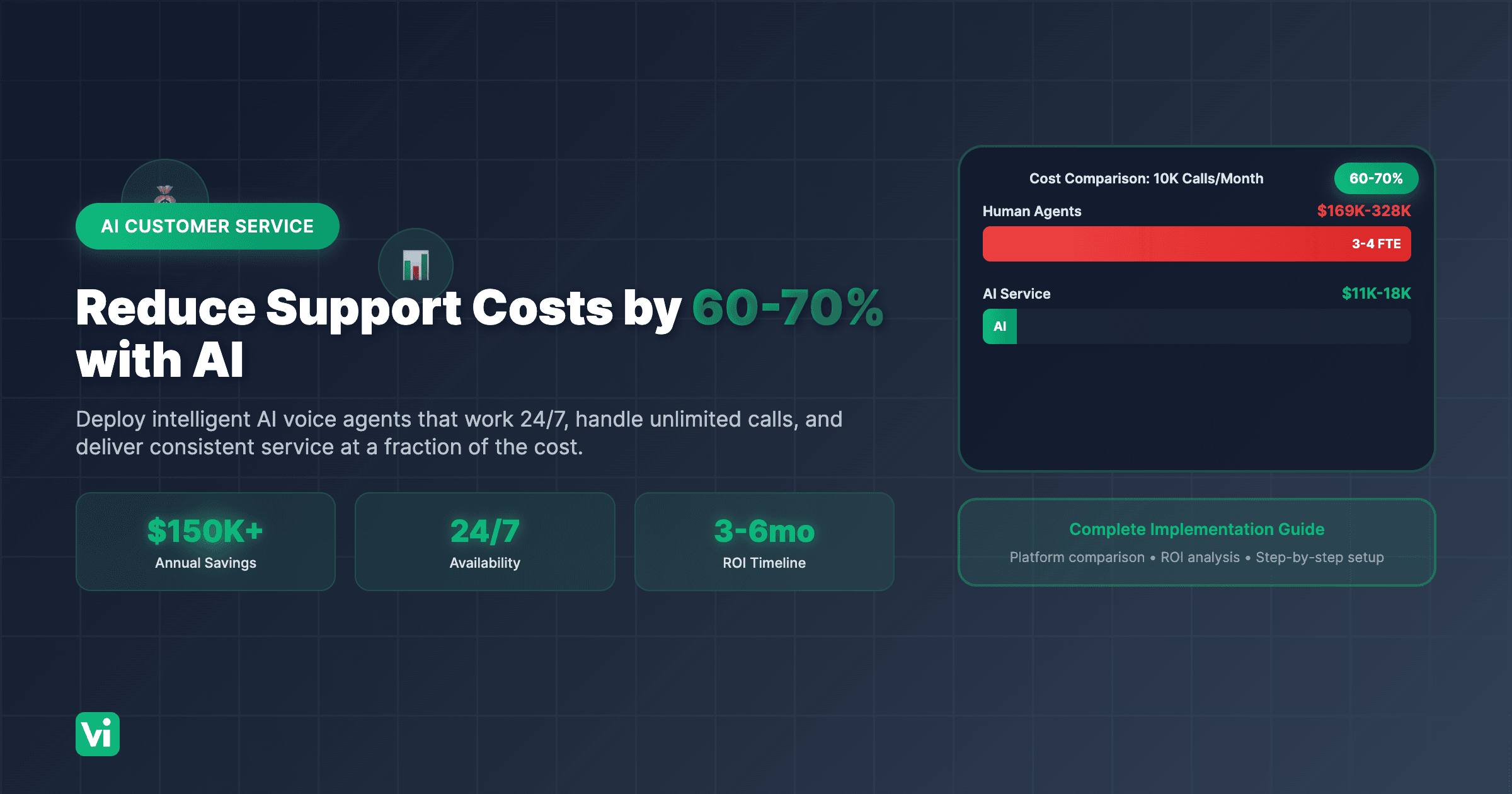
Results: Token optimization reduces voice AI response latency by 60-85% while cutting costs by 70% (AWS latency optimization guide, 2025).
4. Emotion Detection and Adaptive Response
What It Is: Integrating real-time sentiment analysis to detect customer emotional state and dynamically adjust conversation tone, pacing, and escalation decisions.
Why It Works:
Frustrated customers need empathy and immediate solutions, not scripted responses
Confused customers benefit from slower pacing and more straightforward explanations
Satisfied customers prefer efficient, brief interactions
Emotion-aware agents build trust and reduce escalation rates
Implementation:
EMOTION DETECTION FRAMEWORK:
Detect sentiment from:
Voice tone and pitch variationsSpeaking pace (rushed = frustrated, slow = confused)Word choice and language patternsSilence duration and frequency
ADAPTIVE RESPONSES:
Frustration detected (raised voice, negative language):Acknowledge immediately: "I understand this is frustrating"Take ownership: "Let me help resolve this right away"Provide specific action: "Here's what I can do for you..."Escalate if needed: "I'd like to connect you with my supervisor who can help further"
Confusion detected (repeated questions, uncertainty):
Slow down pacingBreak information into smaller stepsConfirm understanding: "Does that make sense so far?"Offer alternative explanation: "Let me explain that differently"
Satisfaction detected (positive language, agreement):
Maintain efficient paceReinforce positive outcome: "Great, I'm glad that worked"Offer additional help briefly: "Anything else I can assist with?"
Results: Emotion-aware voice agents improve customer satisfaction by 35% and reduce call abandonment by 40% (Sentiment analysis research, 2025).
5. Guardrails and Safety Mechanisms
What It Is: Implementing explicit boundaries, hallucination prevention, and escalation logic to ensure voice agents stay accurate, compliant, and trustworthy.
Why It Works:
Prevents agents from inventing information or making unauthorized promises
Ensures compliance with legal requirements and brand guidelines
Builds customer trust through consistent, reliable responses
Reduces liability from incorrect information or off-brand communication
Guardrail Implementation:
HALLUCINATION PREVENTION:
Before providing factual information:Check: Do I have this information in my knowledge base?If YES: Cite source and provide information "According to our current pricing, [information]"If NO: Acknowledge limitation and escalate "I don't have that specific information. Let me connect you with someone who can help."NEVER guess or invent information
CONFIDENCE SCORING:
For each response, internally assess confidence:
High (90-100%): Proceed with responseMedium (70-89%): Add qualifier "Based on available information, [response]"Low (<70%): Escalate to human "This requires specialist knowledge. Let me transfer you."
COMPLIANCE BOUNDARIES:
Hard-coded redlines (never violate):
Cannot process payments or access financial dataCannot make promises outside company policyCannot share confidential business informationMust provide required legal disclaimers for regulated industries
ESCALATION TRIGGERS:
Automatically escalate when:
Customer explicitly requests human agentNegative sentiment persists for 3+ turnsQuestion falls outside knowledge base scopeCompliance or legal topic detectedTechnical issue prevents task completion
Results: Proper guardrails reduce hallucination rates from 27% to under 5% and improve compliance adherence by 96% (Gladia voice AI safety research, 2025).
Building Production-Ready Voice AI Agents
Step-by-Step Implementation Framework
Phase 1: Define Voice-Specific Objectives (Week 1)
Identify Voice Use Cases:
What conversations should your voice AI handle?
What does natural conversation success look like?
What are the voice-specific failure modes to prevent?
How will you measure voice agent performance?
Example Objectives:
"Answer 80% of customer calls with <300ms response time"
"Maintain natural conversation flow with <5% interruption conflicts"
"Detect and adapt to customer emotions in real-time"
"Reduce average call duration by 40% while improving satisfaction"
Phase 2: Design Voice-Optimized System Prompts (Week 1-2)
Apply the voice-specific system prompt techniques covered in the "Proven Techniques" section above. Focus on:
Identity and personality definition
Voice-specific speaking guidelines (pacing, brevity, clarity)
Knowledge boundaries and access limitations
Behavioral guidelines (ALWAYS/NEVER rules)
Conversation flow structure (greeting → resolution → closing)
Phase 3: Implement Voice-Specific Error Prevention (Week 2-3)
Apply the turn-taking, emotion detection, and latency optimization techniques from the "Proven Techniques" section. Key implementation steps:
Configure Voice Activity Detection (VAD) with 300-500ms silence threshold
Enable barge-in handling to stop within 200ms when interrupted
Integrate real-time sentiment analysis for emotion detection
Optimize token usage (200-500 tokens for system prompts)
Enable streaming responses to reduce perceived latency
Configure latency-optimized models (GPT-4o Mini Realtime, Groq)
Phase 4: Build Robust Knowledge Base and Tool Integration (Week 3-4)
RAG-Powered Knowledge Base:
KNOWLEDGE BASE STRUCTURE:
Document Types:
Product specifications and pricingCompany policies and proceduresFAQ and common questionsTroubleshooting guidesLegal disclaimers and compliance requirements
Retrieval Strategy:
Customer asks questionExtract key entities and intentQuery knowledge base with semantic searchRetrieve top 3 most relevant passages (500 tokens max)Inject into prompt as contextGenerate response grounded in retrieved informationCite source when providing factual information
Example:
Customer: "What's your return policy?"
Agent: "According to our return policy, you can return items within 30 days of purchase with original receipt for a full refund. Would you like me to start a return for you?"
Function Calling and MCP Integration:
REAL-TIME TOOL ACCESS:
Available Functions:
check_order_status(order_id) → Returns shipping and delivery informationbook_appointment(date, time, service_type) → Schedules appointmentverify_customer(phone_number, email) → Validates customer identitycheck_inventory(product_id) → Returns real-time stock availabilitycreate_support_ticket(issue_description) → Escalates to human support
Function Calling Best Practices:
Validate inputs before calling functionProvide context to customer: "Let me check that for you..."Handle errors gracefully: "I'm having trouble accessing that information right now"Confirm results: "I see your order is scheduled for delivery tomorrow"Offer next steps: "Would you like me to send tracking details to your phone?"
Model Context Protocol (MCP):
Enable real-time API integrations during callsAccess CRM data, inventory systems, scheduling toolsUpdate records automatically based on conversationMaintain conversation context across system interactions
Phase 5: Test, Iterate, and Deploy (Week 4+)
Comprehensive Testing Framework:
Create Voice-Specific Test Scenarios:
Common customer inquiries (60%)
Edge cases and unusual requests (25%)
Adversarial inputs designed to trigger errors (15%)
Voice-Specific Evaluation Metrics:
Response latency: Average time from customer stops speaking to agent begins response (target: <300ms)
Turn-taking accuracy: Percentage of conversations without interruption conflicts (target: >95%)
Emotion detection accuracy: Correct identification of customer sentiment (target: >85%)
Conversation naturalness: Human evaluation of how natural agent sounds (target: 4.5/5)
First-call resolution: Percentage of issues resolved without escalation (target: >80%)
Hallucination rate: Frequency of invented or incorrect information (target: <5%)
Iteration Process:
Run 100+ test calls covering all scenarios
Analyze failures and identify patterns
Refine prompts to address specific failure modes
Optimize for latency, naturalness, and accuracy
Re-run evaluation to measure improvement
Repeat until performance targets are met
Gradual Rollout:
Start with 10% of call volume to test in production
Monitor real-time performance metrics and customer feedback
Collect edge cases and conversation breakdowns
Expand to 25%, 50%, then 100% as confidence grows
Ongoing Optimization:
Review call transcripts weekly for improvement opportunities
Track latency, emotion detection, and escalation patterns
Update knowledge base as business information changes
Refine prompts based on real-world performance data
A/B test prompt variations to optimize continuously
Advanced Voice AI Prompt Engineering Techniques
Multi-Language and Accent Handling
Language Detection and Switching:
MULTILINGUAL SUPPORT:
Automatic Language Detection:
Detect customer's language from first utteranceRespond in detected language immediatelyIf uncertain, ask: "Would you prefer English, Spanish, or another language?"Maintain language consistency throughout conversation
Cultural Adaptation:
Adjust formality based on language and culture (Formal: German, Japanese; Casual: American English, Australian English)Adapt greetings to time of day and region (Morning/afternoon/evening greetings vary by culture)Use culturally appropriate expressions and idiomsAdjust pacing and directness based on cultural norms
Accent Optimization:
Match voice accent to customer's region when possibleAmerican English for US customersBritish English for UK customersRegional Spanish variants (Castilian, Mexican, Argentine)Ensure pronunciation clarity for non-native speakers
Results: VoiceInfra supports 30+ languages with native-quality voices, enabling global customer service without language barriers.
Personality Design and Brand Voice
Creating Consistent Voice Personality:
PERSONALITY FRAMEWORK:
Define Core Traits (choose 3-5):
Professional yet approachableEmpathetic and patientEfficient and solution-focusedWarm and friendlyKnowledgeable and confident
Translate Traits to Voice Behaviors:
Professional yet approachable:
Use clear, proper grammar without being stiffInclude occasional contractions ("I'll" instead of "I will")Maintain respectful tone while being conversationalExample: "I'd be happy to help you with that"
Empathetic and patient:
Acknowledge customer emotions explicitlyNever rush customers or show impatienceUse validating language ("That makes sense," "I understand")Example: "I can hear this has been frustrating. Let's get this resolved for you"
Efficient and solution-focused:
Get to the point quickly without unnecessary preambleProvide clear next steps and timelinesAvoid over-explaining unless customer asksExample: "I can fix that now. It'll take about 2 minutes"
Error Recovery and Conversation Repair
Handling Misunderstandings:
CONVERSATION REPAIR STRATEGIES:
When Agent Misunderstands:
Acknowledge immediately: "I'm sorry, I didn't catch that"Ask for clarification: "Could you repeat that for me?"Offer specific options if context is clear: "Did you say [option A] or [option B]?"Don't make customer repeat entire explanation
When Customer Misunderstands:
Gently correct: "Let me clarify that..."Rephrase in simpler termsProvide example if helpfulCheck understanding: "Does that make more sense?"
When Technical Issues Occur:
Acknowledge problem: "I'm having trouble hearing you clearly"Suggest solution: "Could you try speaking a bit louder?"Offer alternative: "Would you prefer I call you back on a different line?"Escalate if persistent: "Let me connect you with someone who can help"
Recovery from Dead Ends:
If conversation stalls: "Let me approach this differently..."If customer seems confused: "I may not have explained that well. Here's what I mean..."If agent lacks information: "I don't have that information, but I can connect you with someone who does"
Voice-Specific Compliance and Legal Considerations
Regulatory Requirements:
COMPLIANCE FRAMEWORK:
Call Recording Disclosure:
Inform customer at beginning of call"This call may be recorded for quality and training purposes"Obtain consent in jurisdictions requiring itProvide opt-out option where legally required
Required Disclaimers:
Financial services: "This is not financial advice"Healthcare: HIPAA compliance and privacy noticesLegal services: "This does not constitute legal advice"Insurance: State-specific disclosure requirements
Data Privacy:
Never request sensitive information unless necessaryVerify customer identity before discussing account detailsInform customers how their data will be usedProvide option to speak with human for sensitive matters
Consent Management:
Obtain explicit consent for marketing communicationsRespect do-not-call preferencesHonor opt-out requests immediatelyDocument all consent interactions
Common Voice AI Prompt Engineering Mistakes (And How to Fix Them)
Mistake 1: Using Text Chatbot Prompts for Voice
Problem: Applying text-based chatbot prompts to voice AI creates verbose, unnatural responses that sound robotic when spoken aloud.
Solution: Design prompts specifically for spoken conversation with explicit voice guidelines.
BAD (Text-optimized):
"Thank you for contacting our customer support team. I would be delighted to assist you with your inquiry today. Please provide me with your account number and a detailed description of the issue you are experiencing, and I will do my best to resolve it for you in a timely manner."
GOOD (Voice-optimized):
"Hi, I'm here to help. What can I do for you today?"
[Customer explains issue]
"Got it. Let me pull up your account and fix that for you."
Mistake 2: No Turn-Taking or Interruption Strategy
Problem: Voice agents without proper turn-taking logic talk over customers, cut them off mid-sentence, or create awkward pauses that break conversation flow.
Solution: Implement Voice Activity Detection (VAD) and explicit turn-taking rules.
Add to system prompt:
"TURN-TAKING RULES:
- Wait 300-500ms after customer stops speaking before responding
- If customer speaks again during wait, reset and listen
- If customer interrupts you mid-response, stop immediately and listen
- Use phrase endpointing to detect natural sentence completion
- Never talk over the customer"
Mistake 3: Ignoring Latency and Response Speed
Problem: Verbose prompts and inefficient retrieval create response delays over 1 second, making conversations feel unnatural and robotic.
Solution: Optimize prompts for token efficiency and enable streaming responses.
INEFFICIENT (1,200ms latency):
System prompt: 2,000 tokens of detailed instructions
Context injection: Entire knowledge base (10,000 tokens)
Response generation: Wait for complete response before speaking
OPTIMIZED (200ms latency):
System prompt: 300 tokens of concise, focused instructions
Context injection: Only relevant retrieved passages (500 tokens max)
Response generation: Stream response, begin speaking immediately
Impact: Latency optimization reduces response time by 60-85% while improving conversation naturalness by 70%.
Mistake 4: No Emotion Detection or Adaptive Response
Problem: Voice agents that maintain the same tone regardless of customer emotional state feel robotic and fail to build trust or de-escalate frustration.
Solution: Integrate real-time sentiment analysis and adaptive response protocols.
Add to system prompt: "EMOTION DETECTION AND RESPONSE:
If customer sounds frustrated (raised voice, negative language):
Acknowledge: 'I understand this is frustrating'Show empathy: 'I'd be frustrated too'Take action: 'Let me fix this right away'Escalate if needed: 'I want to get you to someone who can help immediately'
If customer sounds confused (repeated questions, uncertainty):
Slow down your pacingSimplify explanationBreak into clear stepsCheck understanding: 'Does that make sense?'
If customer sounds satisfied (positive language, agreement):
Reinforce: 'Great, I'm glad that worked'Be efficient: 'Anything else I can help with?'Close warmly: 'Thanks for calling'"
Mistake 5: Missing Guardrails and Safety Mechanisms
Problem: Voice agents without explicit boundaries invent information, make unauthorized promises, or provide incorrect answers that damage trust and create liability.
Solution: Implement hallucination prevention and clear escalation logic.
Add to system prompt: "GUARDRAILS AND SAFETY:
Before providing factual information:
Check: Do I have this information in my knowledge base?If YES: Provide information and cite sourceIf NO: Say 'I don't have that specific information. Let me connect you with someone who can help.'NEVER guess or invent information
Automatic escalation triggers:
Customer explicitly requests human agentNegative sentiment persists for 3+ turnsQuestion falls outside knowledge base scopeCompliance or legal topic detectedConfidence level below 70%
When escalating:
Explain reason: 'This requires specialist knowledge'Provide context to human agentDon't make customer repeat information"
Frequently Asked Questions About Voice AI Prompt Engineering
How is voice AI prompt engineering different from text chatbot prompting?
Voice AI requires conciseness (60-70% shorter responses), explicit turn-taking rules to avoid talking over customers, extreme latency optimization (<300ms target), verbal clarity for spelling out information, and real-time emotion detection. Text chatbots don't face these constraints since users can skim and re-read content.
What response latency should I target?
Target <300ms for natural conversation flow. Achieve this through token-optimized prompts (200-500 tokens), streaming responses, fast retrieval (<100ms), latency-optimized models (GPT-4o Mini Realtime, Groq), and prompt caching.
How do I handle interruptions and turn-taking?
Implement Voice Activity Detection (VAD) with 300-500ms silence threshold, enable barge-in to stop within 200ms when interrupted, use phrase endpointing for natural sentence completion, and handle silence progressively (3s, 6s, 10s prompts).
What's the best way to prevent hallucinations?
Use RAG integration to ground responses in verified knowledge, add explicit "check knowledge base first" instructions, implement confidence scoring (escalate below 70%), require source citations, and audit call transcripts weekly. This reduces hallucinations from 27% to <5%.
Should I use different prompts for different use cases?
Yes. Tailor prompts to specific use cases: customer support (empathetic, problem-solving), appointment scheduling (efficient, confirmatory), lead qualification (consultative), collections (firm but respectful), healthcare (HIPAA-compliant). Use-case-specific prompts improve performance by 40-60%.
The Future of Voice AI Depends on Prompt Engineering
The businesses that thrive with voice AI won't be those with the biggest models or the most data; they'll be those that master the art and science of voice-specific prompt engineering.
The underlying technology doesn't determine the naturalness of your voice AI agent. It's determined by how well you engineer the prompts that guide voice-specific conversations.
Proper voice AI prompt engineering transforms robotic automation into natural, human-like interactions that customers prefer over traditional phone systems. It reduces latency, improves conversation flow, optimizes costs, and delivers consistent experiences that build trust and drive revenue.
Ready to build voice AI agents that sound human?
Get started with VoiceInfra:https://voiceinfra.ai/sales
VoiceInfra provides enterprise-grade voice AI infrastructure with low latency, multi-provider LLM access (OpenAI GPT Realtime, Anthropic, Gemini, Groq), RAG-powered knowledge bases, Model Context Protocol integration, and premium voice synthesis (ElevenLabs, Cartesia, Rime Labs). Build natural, human-like voice agents with optimized prompts, deploy in 60 seconds, and scale with confidence. Transform your customer communication with voice AI that actually sounds human.