How Speech-to-Text Works in Voice AI Agents (2026 Guide) | VoiceInfra
Voice AI
How Speech-to-Text (STT) Works in Voice AI Agents
Every voice AI agent starts with a problem: the caller is speaking and the system needs to understand what they said, accurately, in real time. That's the STT engine's job. This guide breaks down exactly how it works, what makes one engine better than another, and what you should measure in production.
MH
Muzamil Hussain
Software Engineer
June 9, 2026
9 min read
Share
Every voice AI agent starts with a problem: the caller is speaking, and the system needs to understand what they said.
Not approximately. Not after a 3-second pause. Not by guessing from context. Accurately, in real time, while the conversation is still happening.
That's the job of the speech-to-text engine, and it's harder than it sounds. The STT layer is where most voice AI deployments quietly lose quality without anyone realising why. Callers get misunderstood. The LLM generates wrong responses. The agent asks for information it already received. And everyone blames the AI model.
Most of the time, the model is fine. The STT layer is the problem.
This guide explains exactly how speech-to-text works inside a voice AI agent, what makes one STT engine better than another, and what you should actually be measuring in production.
What Is Speech-to-Text in the Context of Voice AI?
Speech-to-text (STT), also called automatic speech recognition (ASR), is the component that converts spoken audio into text that the rest of the system can process.
In a traditional transcription tool, STT works on a finished recording. The audio file is complete, the engine processes it, and you get a transcript minutes later. Accuracy can be high because the engine has the full context of everything said.
In a voice AI agent, none of that applies.
The STT engine is processing a live phone call in real time. The caller is still speaking. The audio stream is continuous. There's no "finished file" to analyse, the engine is converting speech to text word by word, millisecond by millisecond, while the conversation is actively happening.
That changes everything. The accuracy requirements are the same, but the latency constraints are brutal. And the audio conditions are nothing like a clean studio recording.
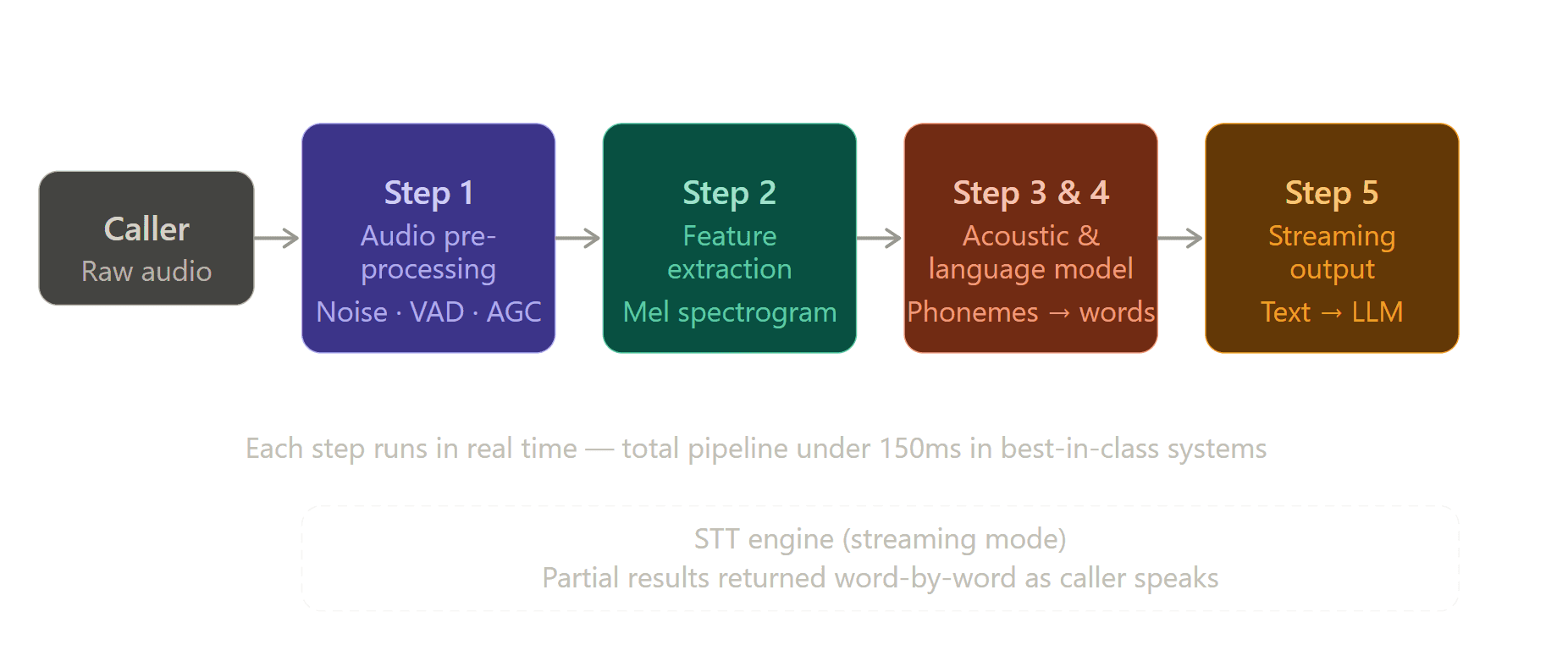
How STT Actually Works: The Technical Process
Understanding what happens under the hood helps explain why some engines perform better than others, and why the gap matters in production.
Ready to Transform Your Business Communications?
Discover how VoiceInfra can help you implement the strategies discussed in this article.
The audio stream arrives from the telephony layer as raw PCM data, typically 8kHz or 16kHz sample rate over a phone call. Before the recognition engine even sees it, the audio goes through preprocessing.
This includes noise reduction to filter out background sounds, echo cancellation to remove the agent's own voice bleeding back into the microphone, automatic gain control to normalise volume levels across loud and quiet callers, and voice activity detection (VAD) to identify when the caller is actually speaking versus silence or background noise.
The quality of this preprocessing step has a direct effect on transcription accuracy. A caller in a noisy environment, on a mobile connection, or speaking into a low-quality microphone will produce degraded audio. Good preprocessing recovers as much signal as possible before recognition begins.
Step 2: Feature Extraction
The preprocessed audio is converted into a numerical representation that the recognition model can work with. The most common approach is a mel-frequency spectrogram, a visual representation of the audio that captures how the frequency content changes over time, weighted to match how human hearing perceives sound.
This step converts the raw audio waveform into a format the neural network can actually process. Think of it as translating the audio from "sound" to "numbers that describe the sound."
Step 3: Acoustic Modelling
The acoustic model is a neural network, typically a transformer-based architecture, that takes the spectrogram and predicts what phonemes (the individual sound units of language) are present in the audio.
This is where accents, speaking pace, background noise, and audio quality have the most impact. A well-trained acoustic model has seen millions of hours of speech across diverse conditions, accents, and audio environments. A poorly trained one breaks on anything outside its training distribution.
Step 4: Language Modelling
The acoustic model produces a probability distribution over possible phoneme sequences. The language model takes that and determines which actual words and sentences are most likely, given both the acoustic signal and the statistical patterns of the language.
This is why STT engines can correctly transcribe "I need to reschedule my Thursday appointment" even when the audio is slightly degraded. The language model knows "Thursday appointment" is a plausible phrase in the context of a scheduling conversation, and it ranks that interpretation higher than acoustically similar but implausible alternatives.
Step 5: Output and Streaming
The final step is delivering the transcript. In batch mode, the full transcript comes back when the audio is complete. In streaming mode, partial results are returned continuously as the caller speaks, word by word, in real time.
For voice AI agents, streaming is essential. It's what allows the LLM to begin processing the caller's intent before they've finished speaking, which is the primary mechanism for achieving sub-800ms end-to-end response times.
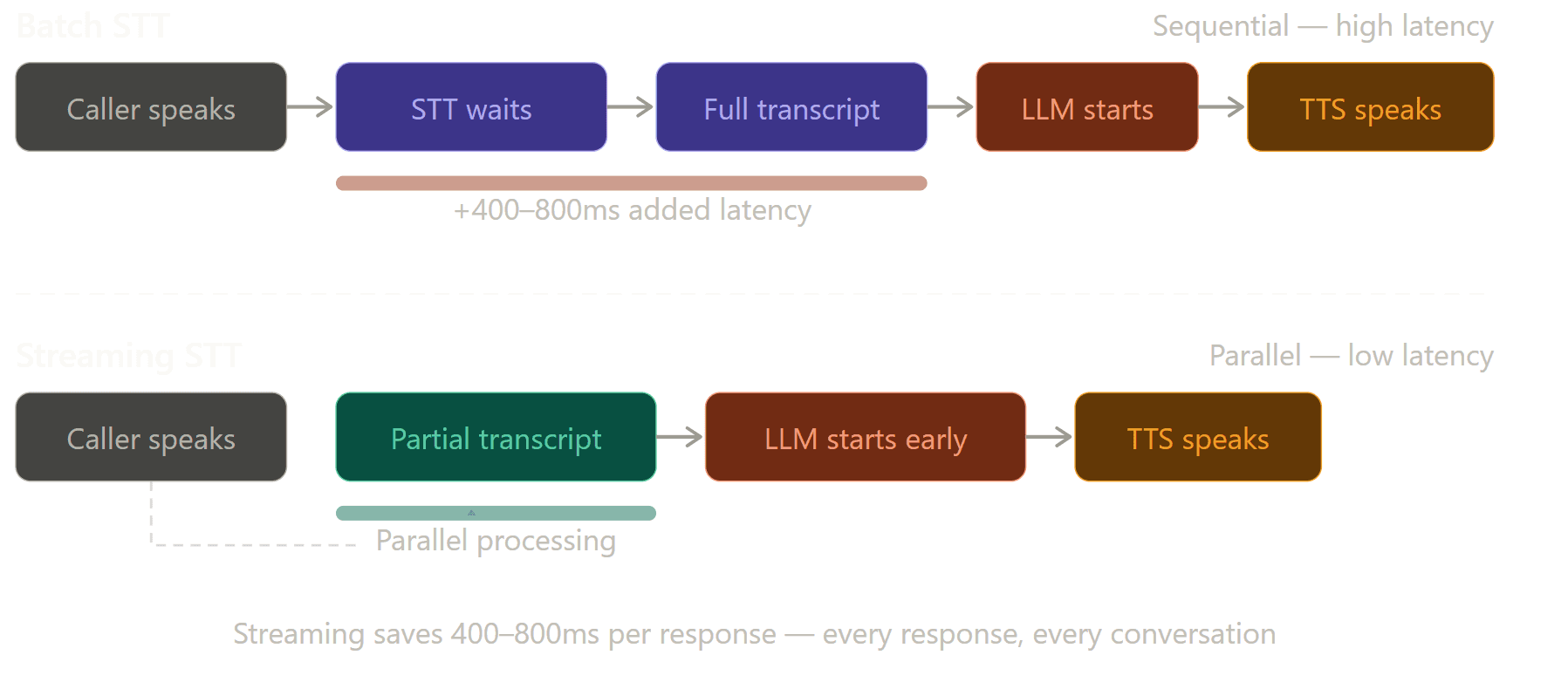
Batch vs Streaming STT: Why It Matters for Voice AI
This distinction directly determines how fast the voice AI agent feels to callers.
Feature
Batch STT
Streaming STT
How it works
Processes complete audio after caller stops
Returns partial results as caller speaks
When transcript arrives
After end-of-speech detection
Continuously, mid-speech
LLM can start processing
Only after full transcript received
While caller is still speaking
End-to-end latency
Higher, sequential processing
Lower, parallel processing
Accuracy
Slightly higher (full context)
Slightly lower (real-time constraints)
Best for
Transcription tools, post-call analysis
Live voice AI agents
The practical impact: a batch STT implementation adds 400 to 800 milliseconds of delay compared to streaming, simply because the LLM cannot start until the full transcript arrives. In a phone conversation, that's the difference between a response that feels natural and one that feels like there's a bad connection.
Every production voice AI agent should be using streaming STT. If a platform is using batch transcription for live calls, that's a significant architectural limitation.
The Two Numbers That Define STT Quality
When evaluating an STT engine for voice AI deployment, two metrics matter above everything else.
Word Error Rate (WER)
Word Error Rate measures how often the STT engine gets words wrong. A WER of 5% means that in a 100-word utterance, approximately 5 words will be wrong. That sounds acceptable until you consider what those 5 words might be. If one of them is a medication name, a policy number, or a key intent word, the downstream consequences are significant.
Use Case
Acceptable WER
Why
General business calls
Under 8%
Most errors are recoverable in context
Healthcare
Under 4%
Medication names, dosages, and patient data require high accuracy
Insurance
Under 5%
Accurate handling of policy numbers and claim details
Financial services
Under 3%
Critical for account numbers and transaction amounts
Logistics
Under 6%
Important for load numbers, addresses, and dates
Latency (Time to First Token)
Latency in STT context means the time from when the caller stops speaking to when the first word of the transcript is available to the LLM. This number has a compounding effect. STT latency + LLM processing time + TTS generation time = total response latency. Shave 200ms off STT and you shave 200ms off every single response in the conversation.
Latency Range
Caller Experience
Under 150ms
Natural, imperceptible delay
150–300ms
Slightly noticeable, still acceptable
300–600ms
Caller notices the pause
Over 600ms
Feels broken, trust erodes
What Makes STT Hard: Real-World Challenges
The benchmarks always show impressive accuracy numbers. Production deployments always surface edge cases the benchmarks don't cover.
Accents and dialects. A model trained primarily on American English will perform noticeably worse on strong regional accents, non-native speakers, or dialectal variations. For businesses serving diverse populations, accent robustness is a first-class requirement, not an afterthought.
Telephony audio quality. Phone calls are not high-fidelity audio. The PSTN compresses audio to a narrow frequency band (300Hz–3400Hz for standard calls). Mobile connections add packet loss and compression artifacts. VoIP calls over poor internet connections introduce jitter and dropouts. The STT engine sees degraded audio as a baseline condition, not an exception.
Speaking style variation. People don't speak the way text is written. They use filler words ("um", "uh", "like"), false starts, self-corrections, and run-on sentences. They speak quickly when nervous and slowly when uncertain. They talk over the agent when impatient.
Domain-specific vocabulary. Generic models struggle with terminology outside their training distribution. Medical procedure names, insurance policy codes, freight terminology, and product-specific language all have higher error rates unless the model has been exposed to them.
Background noise. Call centres, warehouse floors, car interiors, and busy waiting rooms are all real environments where callers make calls. Background noise is not an edge case, it's the normal condition for a significant percentage of inbound calls.
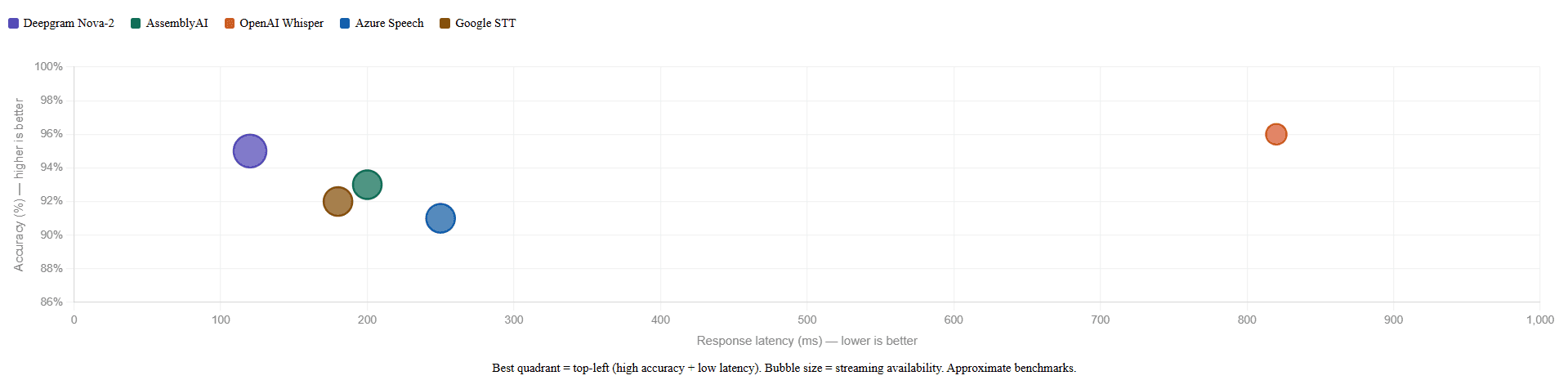
STT Provider Comparison
The major STT providers each have different strengths. Choosing the right one depends on your use case, latency requirements, language coverage, and budget.
Provider
Streaming
WER (general)
Latency
Best for
Deepgram Nova-2
✅ Yes
~5–7%
~120ms
Low latency, production voice AI
AssemblyAI
✅ Yes
~6–8%
~200ms
Accuracy + analytics features
OpenAI Whisper
❌ Batch only
~4–6%
~800ms+
Post-call transcription
Azure Speech
✅ Yes
~7–9%
~250ms
Enterprise compliance
Google STT
✅ Yes
~6–8%
~180ms
Multilingual, Google Cloud
Whisper's accuracy is excellent but its standard implementation is batch-only, not suitable for live voice AI without significant engineering. Deepgram leads on latency for production voice applications. AssemblyAI adds useful post-processing features (speaker diarisation, sentiment analysis) that are valuable for call analytics.
For most production voice AI deployments, Deepgram or AssemblyAI are the practical choices.
How STT Connects to the Rest of the Voice AI Stack
The STT engine doesn't operate in isolation. Its output quality directly affects everything downstream.
STT → LLM. The LLM receives the text transcript and makes decisions based on it. If the transcript contains errors, the LLM works with wrong information. "Reschedule Thursday" and "reschedule thirsty" produce very different downstream actions. The LLM cannot compensate for STT errors it doesn't know occurred.
STT latency → total response time. STT latency is additive with LLM processing time and TTS generation. Optimising STT latency is one of the highest-leverage improvements available because it affects every response in every conversation.
STT accuracy → containment rate. Higher STT accuracy means more calls handled without human intervention. Even a 2% improvement in WER translates to measurable improvements in containment rate for high-volume deployments.
STT → analytics. Post-call transcripts are produced by the STT engine. The quality of those transcripts determines the quality of call analytics, intent classification, and the data used to improve the agent over time. Poor STT quality poisons the analytics pipeline.
What to Look for When Evaluating STT for Voice AI
Requirement
What to check
Streaming support
Does it return partial results in real time?
Latency under load
What's the p95 latency at 100+ concurrent calls?
Accent coverage
Test with your actual caller demographics
Domain vocabulary
Test with terminology specific to your industry
Telephony audio handling
Test with 8kHz compressed audio, not clean recordings
Background noise robustness
Test with realistic ambient noise conditions
Language support
Does it cover the languages your callers speak?
Cost at scale
Per-minute pricing across expected call volume
The most important test is always to use your own audio. Benchmark numbers are produced in controlled conditions. Your callers will have accents, background noise, and speaking styles that the benchmark audio doesn't represent. Test on recordings from your actual call environment before committing to an STT provider.
Final Thought
The STT engine is where every voice AI conversation begins. Get it wrong and every component downstream is working with flawed input, the LLM, the orchestration layer, the analytics, all of it.
Most teams spend far more time evaluating LLMs than they spend evaluating STT engines. That's backwards. The LLM can reason brilliantly with accurate input. It cannot compensate for a transcript that says "thirsty appointment" when the caller said "Thursday appointment."
Evaluate your STT layer as carefully as you evaluate your LLM. Test on real audio from your actual environment. Measure latency under production load conditions, not demo conditions.
The conversations your voice AI agent handles every day start here.
Want to see how VoiceInfra handles STT routing and optimisation in production?Schedule a demo and we'll walk you through the full stack.